

Normalization

image from めたたろう
最近刚好追溯到layer normalization这个正则化方法的论文,感觉稍微有些理解了便做一下记录,也分享一些相关的知识。
具体论文: Layer Normalization
前置知识
RNN
recurrent Neural Network,即循环神经网络,由于还没有仔细读过相关的论文,具体实现细节就不进行叙述了,只用自己的话解释一下:
RNN相对于一般FNN来说,一个很关键的区别就是RNN具有循环连接,其作用是将上一个时序的一些信息(经过激活函数前的信息)同样也作为输入,和input一起作为输入传给下一层的网络,具体实现大概如下:
这里设时间序为t-1时刻的隐藏层的输出为,时间序t时刻的输入为,为该层神经元输入总和的向量表示,为t时刻对于输入总和进行的相关偏置,f为激活函数,则有一下公式:
一般RNN由于其时序性,可以使在处理当前层的时候无法看到后续层的信息,所以一般用来进行有关Seq2Seq的任务,比如:自然语言处理、语音识别等
有关NLP任务的前置处理方法
对于NLP任务,这里以翻译任务来举例,一般来说是将一段原数据(比如很多英语句子),转化为处理好后的数据(比如与之对应的中文句子)
这里的每一个英语句子都可以看作一个sample,一般我们会先做一下处理:
Tokenization(分词)
将文本拆分为:
-
字符级(character-level)
-
子词级(subword,如 BPE[Byte Pair Encoding]、SentencePiece)
-
单词级(word-level)
一般从以上方法种选取一种作为主分词方法
eg:
文本: "我喜欢学习"
→ ["我", "喜欢", "学习"]文本: "unhappiness"
→ ["un", "happiness"] (BPE)转换成 ID(映射到词表索引)
通过词表(Vocabulary)将 Token 映射为整数:
["我", "喜欢", "学习"] → [102, 532, 884]Embedding(嵌入)
将整数 ID 转换为稠密向量:
[102, 532, 884] →
[
[0.12, -0.53, ...],
[0.34, 0.21, ...],
[-0.88, 0.04, ...],
]经过上述前置处理流程,得到的embedding向量就可以用于处理数据的不同NN架构了
layer norm vs batch norm
由于RNN中需要通过反向传播依靠gradient来更新参数,而由于层与层之间具有很强的传递与关联性,可以理解到如果每一个时间序列(层)的贡献过大,则后续的层也会继续积累这个很大的贡献,最后导致梯度爆炸,文中的内容如下:
递归单元的总输入的平均大小在每个时间步都有可能增长或缩小,从而导致梯度爆炸或梯度消失。所以我们需要一种可以使在每一层得到相应的后,对其进行相应的归一化,使其可以对于下一个贡献有不扩张性(可以理解成通过对于进行调整使其在t时间的整体性内处于稳定),于是我们需要选择相应的归一化方法
batch normlization
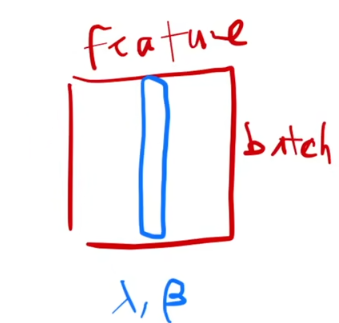
简单理解,如它的名字一样,每次对于一个batch的样本的同一个feature进行归一化处理,具体可见如下图片(出自李沐老师的视频中):
二维情况:
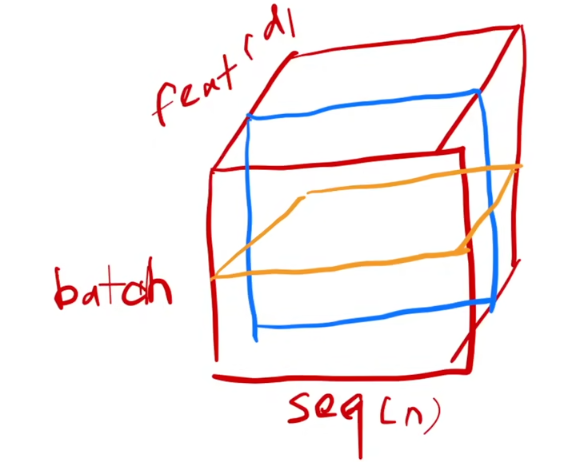
三维情况(图中蓝色框):
layer normlization
基本介绍
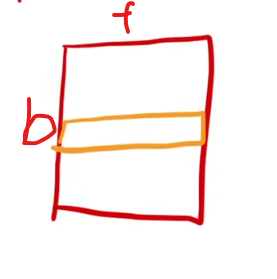
这里因为RNN中,每一层其实是对每一个sample的所有features做操作,所以顾名思义它是针对 同一层(layer)内所有神经元(特征维度)做归一化,具体可见如下图片(出自李沐老师的视频中):
二维情况:
三维情况(图中黄色框):
对比
现在我们对这两种归一化方式有了一定的了解,于是我们来考虑为什么在RNN中使用Layer norm:
一般在训练FNN时候,我们通过使用归一化的方式,可以在train的时候提前存储好整个训练数据的sum_mean和sum_variance,由于基本的layer是固定且稳定的,于是便可以在推理时直接应用,相当于一个预处理
而回到RNN,首先对于train_data 和 test_data,两者其实是可以没有太大任何关联的,这就可能会导致train时候的句子在每一个feature上体现的效果(可以理解为贡献的大小)可能比较稳定,但到了推理时候句子可能会在每一个feature上体现的效果很不稳定,参差不齐,甚至可能出现原来只出现过长度贡献为100的feature,而在推理时出现了长度贡献为200的feature(可以结合下面的图进行相应的理解,每一条其实就是使用batch norm方法所有sample对应的特定的feature贡献),所以如果用batch norm就会导致这种偏差问题。同时,由于RNN每次是对一个sample进行处理,倘若使用batch norm,则需要在每一个时间序中进行对于一个feature的sum_mean和sum_variance的分别存储,这十分的不方便。
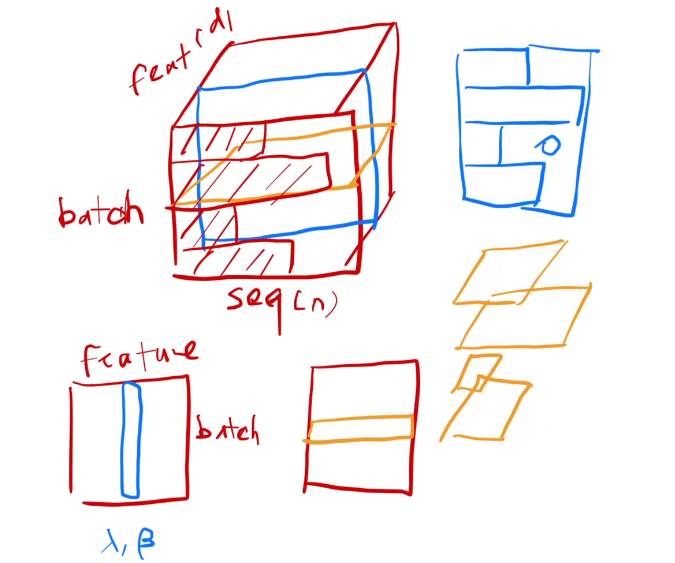
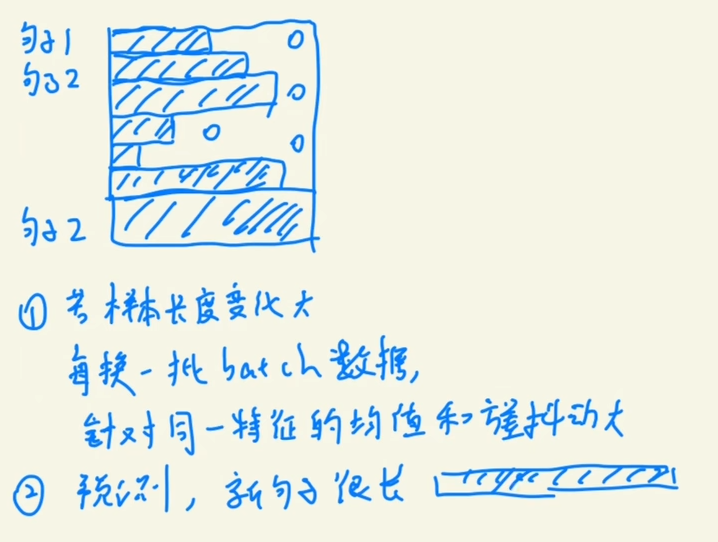
于是便出现了layer norm,基于RNN结构的归一化方式:
通过直接对于每一层(每一个时序t)进行对于每一个sample的所有feature进行归一化,贴合网络架构去进行归一化,同时也不需要统计所有样本的总mean和variance,而是单独计算每一个sample的即可,同样在推理的时候也这么处理就好。 具体的实现细节可以看如下论文中的内容:

注:batch norm归一化计算也是类似的,通过给原数据减去均值之后divide方差得到,同时拥有两个可学习参数和去具体根据需求进行相应的匹配调整,具体公式如下:
注:其中为一个很小的数,为了防止方差接近于0导致得到的结果非常大
完结撒花🌼🌼🌼~